Which programming language would you use to analyse an XML file? Nine times out of ten the answer would be XPath. Either as a standalone language or hosted by a language like XSLT, XQuery or Python. Now for a more difficult question: How would you develop and test your XPath, explore XPath 3.1’s new types like maps and arrays, or perhaps describe and share a set of XPath expressions with others? Here I’m going to propose why XPath Notebooks could well be the answer to this question.
XPath Notebook Overview
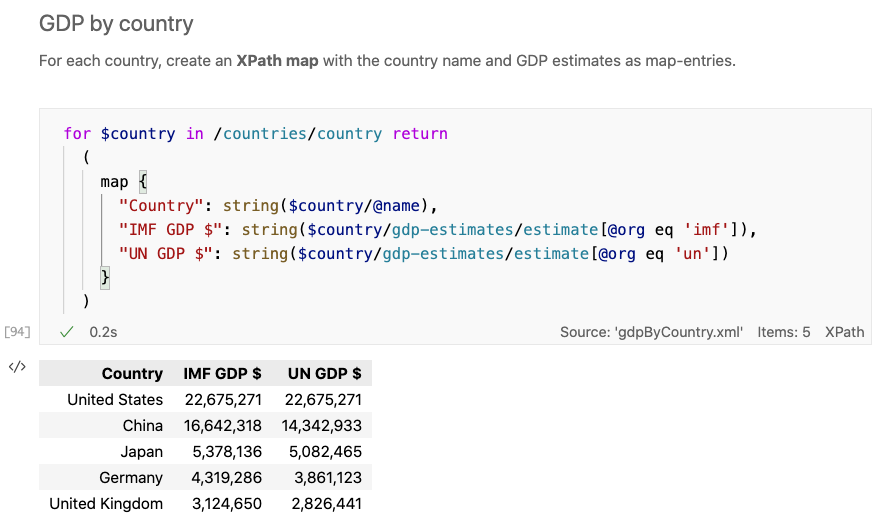
An XPath Notebook is a document comprising a set of input and output cells. Input cells can either be markdown cells or code cells (in this case XPath). An output cell immediately follows an executed code cell. It can render the result from the code cell as a table, as in the screenshot below, JSON syntax, or some other representation like a plot or a chart.

DeltaXML’s XPath Notebook Extension
XPath Notebook is a light-weight extension that brings XPath 3.1 language and XML analysis features to Visual Studio Code’s rich Notebook ecosystem.
Visual Studio Code has again (2021) been voted the most popular code editor for the majority of software developers. It’s open-source and cross-platform. Managed by Microsoft, it is enhanced by an extensive range of community supported extensions.
Notebook Output Cell View Types
Notebook output cells are the dynamic part of a notebook. They render the result of an executed code cell (all code cells can be executed in a single sequence or individually).
The view type of an output cell is changed using the button adjacent to the output cell. A number of view types are available:
Table View
In the XPath Notebook view above, the output cell is rendered as a table. The actual code cell result here is an XPath sequence of map items. The table view type presents this output in a more readily digestible way.
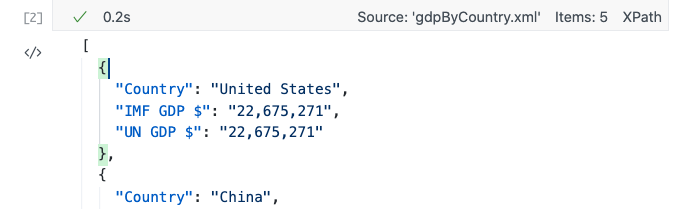
Raw JSON View
The JSON view type is helpful when just testing XPath code or to help develop the structure required by other richer data-views. With the JSON output cell view type, XPath Data Model (XDM) arrays and sequences are represented as JSON arrays, XDM maps are represented as JSON objects with each property corresponding to a map-entry as seen below:

XML Node Results in JSON
In the case of XML nodes, the node item is rendered in the JSON as a specially highlighted XPath location which, when clicked while holding the ⌘ button, will take you to the corresponding XML element or attribute in the source XML.
Externally Rendered Views
Visual Studio Code extensions help visualise output cell data in even more ways. For example, the Summary View from Random Fractals extension renders the result in a graphical way as shown below. Note the data here is not quite in the form needed by the renderer but hopefully it gives the idea:

Evaluation Context
XPath expressions often need to exploit a static or dynamic evaluation context. For XPath Notebooks this context is setup for you: The static context hosts the static base-URI along with Notebook-scoped XPath variables. The dynamic context comprises the source XML document node along with declared XML namespaces and also a set of utility namespaces like those for XPath’s map and array functions.
Source XML
The source XML is always set to the most recent XML file viewed in Visual Studio Code’s environment. You can therefore conveniently change the source by opening another XML file and then returning to the notebook. The source XML filename (gdpByCountry.xml in this case) is shown in the status bar at the bottom of each code cell.
Source JSON
While the focus of this blog is XML analysis, if the most recently opened file in Visual Studio Code happens to be valid JSON then this JSON file is set to be the context-item for XPath evaluation. XPath’s json-doc() function is used to parse the JSON to the equivalent XPath Data Model types.
Notebook Variables
The XPath from one notebook code cell can reference the result of a previously executed cell as an XPath variable. For this, there’s a standard $_ variable that always references the most recently executed cell. You can also assign a specified variable name to a code cell’s result by adding special ‘XPath prologue’ to the code cell.
About Editing XPath
Standalone XPath editors tend to be light-weight and offer limited help for the developer, this is not the case with XPath Notebooks in Visual Studio Code.
In XPath Notebooks you will find a rich XPath editing environment with syntax-highlighting, auto-completion and code-formatting. For problem highlighting, there’s also a responsive syntax-checker that detects most common code errors. The integrity of all variable and function references is also checked.
If a runtime error for a code cell occurs, the error message from the Saxon-JS processor will be shown in the output cell in place of the result.
Editing Markdown
Notebook cells have two modes, a command mode and edit mode. When a markdown cell is in edit mode, the syntax-highlighted raw markdown text is visible. Executing the cell switches the cell to command mode and results in richly styled text. Cells with markdown headings help structure longer notebooks, they also contribute towards a Notebook outline view shown in the vertical Explorer pane.
XPath Notebooks in Practice
For a practical example we’re going to analyse, with the help of an XPath Notebook, a result file from DeltaXML’s XML Data Compare product. In this example, two XML files have been compared and the result we want to analyse contains the input XML but with extra elements/attributes to mark the XML differences found between the A and B input files.
This result file is now opened in Visual Studio which will set it as the source XML:

Note: DeltaXML’s companion XSLT/XPath extension, auto-installed with XPath Notebook, provides general XML features such as the Breadcrumbs and Outline views seen above. It also performs XML well-formedness checking and provides a set of commands for XML Navigation, please see the documentation for more information.
An XPath Notebook is now opened to analyse this file. The Run All button at the top of the notebook is pressed to execute each code cell in sequence. The Tokyo Night Storm colour theme was used for this screenshot:

Markdown cells in this Notebook help explain the purpose of each code cell. The first code cell shows an error occurred when writing the output. This is because the result is an XPath function. This result is assigned to the $version variable (specified in the prologue) as intended but cannot be serialized and rendered in the output cell a useful way.
The second code cell’s output cell uses the table view type. It shows the data for each `person` element with information about whether it occurred in the A or B input files. (The position of the `person` element is also shown to indicate how the data-items have moved.)
A different code cell executed on the same source XML shows how XML nodes are represented in the output cell using the raw JSON view type:

The XML nodes in the output cell are shown with different syntax-highlighting to string-values. If you hover over an XML node result a tooltip will invite you to CMD+click to navigate to the XML node and select it in the source XML file.
Technical Details on XPath Notebooks
For robustness, XPath is evaluated in a separate process hosting a Node.js REPL server. A Saxon-JS XSLT transform is invoked on a compiled XSLT SEF file, with the XPath and JavaScript context object passed as parameters . The XSLT manages the evaluation context, executes the XPath (inside an xsl:evaluate instruction), updates the context object and then converts the result to a JSON representation.
Future Enhancements
We hope to update XPath Notebooks to support the Jupyter project’s ipynb format as soon as it’s fully supported in Visual Studio Code in stable form (expected September 2021).
The ‘ipynb’ format is supported by extensions that provide additional features such as publishing Notebooks in PDF or HTML format.
Summary
There are too many features to cover in this space, but I hope I’ve been able to give a flavour here of what XPath Notebooks can offer.
If you’re interested in exploring XPath Notebooks further please install Visual Studio Code and the required Node.js server along with our extension which is available from DeltaXML’s Visual Studio Code marketplace page.



























Late breaking news: The next update to XPath Notebooks will include axis-aware auto-completion for node-names in XPath location expressions.